
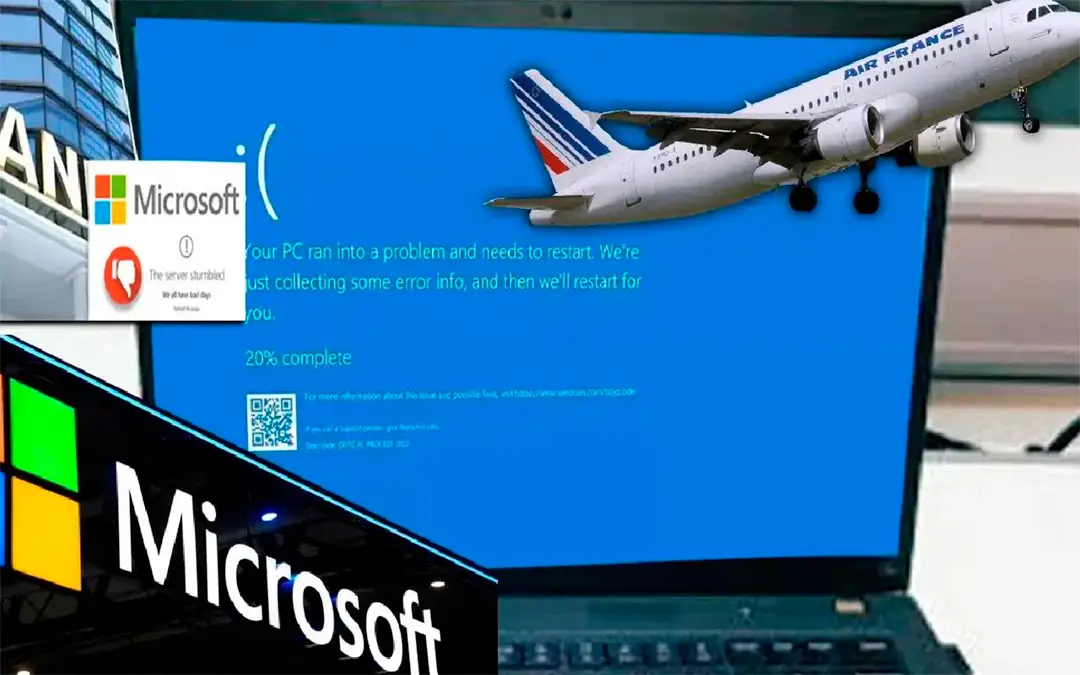
On July 19, 2024, Windows users across the globe faced a significant disruption as many experienced the notorious Blue Screen of Death (BSOD) due to a problematic update from cybersecurity firm CrowdStrike. The incident, which has been described as one of the largest outages in recent history, has prompted a comprehensive investigation into the causes and potential solutions. This article delves into the details of what happened, why it occurred, and how users and organizations can address and prevent similar issues in the future.
The Incident: What Happened?
At approximately 04:09 UTC on July 19, 2024, CrowdStrike, a prominent cybersecurity company known for its Falcon endpoint protection platform, rolled out an update intended to enhance the functionality of its Falcon sensor for Windows. However, this update inadvertently contained a critical logic error that led to widespread system crashes among Windows users. The update caused the Falcon sensor to conflict with core Windows processes, resulting in a flood of BSOD errors.
The impact of this update was immediate and severe. Users reported that their systems were rendered unusable, with frequent and unexpected crashes that prevented them from accessing their data and applications. This widespread disruption affected not only individual users but also businesses and organizations relying on Windows systems for their daily operations.
CrowdStrike’s Response
In response to the chaos, CrowdStrike moved quickly to identify and address the issue. The company’s engineering team was able to pinpoint the problem within hours of the update’s release. They determined that a logic error in the update was responsible for the crashes and promptly began working on a fix.
By 07:45 UTC, CrowdStrike had released a patch to correct the error and stabilize the Falcon sensor. The company also issued a public statement acknowledging the issue and reassuring customers that this was not the result of a cyberattack or security breach. Instead, it was a technical error related to the update process.
CrowdStrike’s swift action helped mitigate further disruptions, but the incident highlighted the importance of rigorous testing and quality assurance in software updates. The company has since committed to enhancing its testing protocols to prevent similar issues in the future.
Impact and Consequences
The impact of the July 19 outage was far-reaching. Businesses experienced significant downtime, with some reporting losses due to halted operations. Individual users faced frustration and potential data loss as a result of the crashes. The incident also drew attention from the broader tech community and media, prompting discussions about the reliability and testing of software updates.
For organizations, this incident underscored the importance of having robust disaster recovery plans and backup solutions. Companies that had contingency measures in place were better equipped to handle the disruption and minimize downtime. However, those without such measures faced more severe consequences.
Recommendations and Best Practices
In light of the CrowdStrike update incident, several best practices can help mitigate the impact of similar events in the future:
- Rigorous Testing: Ensure that all software updates undergo thorough testing in a controlled environment before deployment. This can help identify and address potential issues before they affect end users.
- Disaster Recovery Planning: Develop and maintain comprehensive disaster recovery and business continuity plans. Regularly test these plans to ensure they are effective in minimizing downtime and data loss.
- Backup Solutions: Implement reliable backup solutions to protect critical data. Regular backups can help restore systems and data in the event of a crash or other disruptions.
- User Communication: Communicate clearly and promptly with users about any issues and the steps being taken to resolve them. Transparency helps build trust and can alleviate some of the frustration during an outage.
- Monitoring and Alerts: Set up monitoring systems to detect and alert on potential issues with software updates or other critical components. Early detection can help address problems before they escalate.
The July 19, 2024, Windows crash incident serves as a stark reminder of the potential impact of software updates and the importance of effective testing and recovery measures. While CrowdStrike has taken steps to address the issue and prevent future occurrences, the event highlights the need for ongoing vigilance and preparedness in the tech industry.
As users and organizations navigate the aftermath of this incident, the focus should remain on learning from the experience and implementing best practices to safeguard against future disruptions. By doing so, the industry can better ensure the reliability and resilience of its systems and services.